Вторая часть цикла переводов Redis Best Practices от «Redis Labs», и в ней рассмотрены паттерны взаимодействия и паттерны хранения данных.

Dmitry @RPG18
Golang Developer
Коты в коробочках, или Компактные структуры данных
12 min

Как быть, если дерево поиска разрослось на всю оперативку и вот-вот подопрет корнями соседние стойки в серверной? Что делать с инвертированным индексом, жадным до ресурсов? Завязывать ли с разработкой под Android, если пользователю прилетает «Память телефона заполнена», а приложение едва на половине загрузки важного контейнера?
В целом, можно ли сжать структуру данных, чтобы она занимала заметно меньше места, но не теряла присущих ей достоинств? Чтобы доступ к хэш-таблице оставался быстрым, а сбалансированное дерево сохраняло свои свойства. Да, можно! Для этого и появилось направление информатики «Succinct data structures», исследующее компактное представление структур данных. Оно развивается с конца 80-х годов и прямо сейчас переживает расцвет в лучах славы big data и highload.
А тем временем на Хабре найдется ли герой, способный пересковоговорить три раза подряд
[səkˈsɪŋkt]?
Логические поля в базах данных, есть ли противоядие
9 min

Часто в таблицах содержится большое количество логических полей, проиндексировать все из них нет возможности, да и эффективность такой индексации низка. Тем не менее, для работы с произвольными логическими выражениями в SQL пригоден механизм многомерной индексации о чем и пойдёт речь под катом.
Гильберт, Лебег … и пустота
17 min

Под катом исследуется вопрос, как должен быть устроен хороший алгоритм многомерной индексации. На удивление, вариантов не так уж и много.
Пишем свой capped expirationd модуль для tarantool
8 min

Какое-то время назад перед нами встала проблема чистки кортежей в спейсах tarantool. Чистку нужно было запускать не тогда, когда у tarantool уже заканчивалась память, а заранее и с определенной периодичностью. Для этой задачи в tarantool есть модуль, написанный на Lua, под названием expirationd. После непродолжительного использования этого модуля мы поняли, что нам он не подходит: на постоянных чистках больших объемов данных Lua висел в GC. Поэтому мы задумались о разработке своего capped expirationd модуля, надеясь, что код, написанный на нативном языке программирования, решит наши задачи наилучшим образом.
Хорошим примером нам послужил модуль tarantool под названием memcached. Используемый в нем подход основывается на том, что в спейсе заводится отдельное поле, в котором указывается время жизни кортежа, иными словами, ttl. Модуль в фоне сканирует спейс, сравнивает ttl с текущим временем и принимает решение о том, удалять кортеж или нет. Код модуля memcached простой и элегантный, но слишком общий. Во-первых, он не учитывает тип индекса, по которому осуществляется обход и удаление. Во-вторых, на каждом проходе сканируются все кортежи, количество которых может быть довольно большим. И если в модуле expirationd первая проблема была решена (tree-индекс выделен в отдельный класс), то второй все так же не уделено никакого внимания. Это предопределило выбор в пользу написания своего кода.
Как устроены сервисы управляемых баз данных в Яндекс.Облаке
12 min
Когда ты доверяешь кому-то самое дорогое, что у тебя есть, – данные своего приложения или сервиса – хочется представлять, как этот кто-то будет обращаться с твоей самой большой ценностью.
Меня зовут Владимир Бородин, я руководитель платформы данных Яндекс.Облака. Сегодня я хочу рассказать вам, как всё устроено и работает внутри сервисов Yandex Managed Databases, почему всё сделано именно так и в чём преимущества – с точки зрения пользователей – тех или иных наших решений. И конечно, вы обязательно узнаете, что мы планируем доработать в ближайшее время, чтобы сервис стал лучше и удобнее для всех, кому он нужен.
Что ж, поехали!

Меня зовут Владимир Бородин, я руководитель платформы данных Яндекс.Облака. Сегодня я хочу рассказать вам, как всё устроено и работает внутри сервисов Yandex Managed Databases, почему всё сделано именно так и в чём преимущества – с точки зрения пользователей – тех или иных наших решений. И конечно, вы обязательно узнаете, что мы планируем доработать в ближайшее время, чтобы сервис стал лучше и удобнее для всех, кому он нужен.
Что ж, поехали!
Вопросы для собеседования — от кандидата к работодателю
4 min
Все мы привыкли к тому, что на собеседованиях задают много вопросов. Обычно — работодатели кандидатам. Один из таких вопросов — “а у вас есть вопросы к нам?”. Довольно часто кандидаты не готовы к этому. И зря. Задавать вопросы работодателю — это совершенно нормально и даже необходимо. Лучше сразу уточнить все важные для вас аспекты работы, чем потом разочароваться. Более того, вопросы, заданные кандидатом, иногда даже учитываются как одна из характеристик кандидата. О чем спросил кандидат — о технологиях, о продукте или о процессах?
В этой статье я рассмотрю вопросы, часто задаваемые кандидатами разработчиками ПО. Я считаю, что эта статья будет полезна как самим кандидатам, так и рекрутерам, чтобы подготовиться к собеседованию.
В этой статье я рассмотрю вопросы, часто задаваемые кандидатами разработчиками ПО. Я считаю, что эта статья будет полезна как самим кандидатам, так и рекрутерам, чтобы подготовиться к собеседованию.
Просто и на C++. Основы userver — фреймворка для написания асинхронных микросервисов
6 min
В Яндекс.Такси придерживаются микросервисной архитектуры. С ростом количества микросервисов мы заметили, что разработчики много времени тратят на boilerplate и типичные проблемы, при этом решения не всегда получаются оптимальные.
Мы решили сделать свой фреймворк, с C++17 и корутинами. Вот так теперь выглядит типичный код микросервиса:
А вот почему это крайне эффективно и быстро — мы расскажем под катом.
Мы решили сделать свой фреймворк, с C++17 и корутинами. Вот так теперь выглядит типичный код микросервиса:
Response View::Handle(Request&& request, const Dependencies& dependencies) {
auto cluster = dependencies.pg->GetCluster();
auto trx = cluster->Begin(storages::postgres::ClusterHostType::kMaster);
const char* statement = "SELECT ok, baz FROM some WHERE id = $1 LIMIT 1";
auto row = psql::Execute(trx, statement, request.id)[0];
if (!row["ok"].As<bool>()) {
LOG_DEBUG() << request.id << " is not OK of " << GetSomeInfoFromDb();
return Response400();
}
psql::Execute(trx, queries::kUpdateRules, request.foo, request.bar);
trx.Commit();
return Response200{row["baz"].As<std::string>()};
}
А вот почему это крайне эффективно и быстро — мы расскажем под катом.
PG12: Дюжина патчей от Postgres Professional
7 min
Приятно видеть знакомые фамилии в списке Acknowledgments официального релиза PostgreSQL 12. Мы решили свести вместе попавшие в релиз новшества и некоторые багфиксы, над которыми трудились наши разработчики.
(В Release Notes это звучит как Add support for the SQL/JSON path language (Nikita Glukhov, Teodor Sigaev, Alexander Korotkov, Oleg Bartunov, Liudmila Mantrova)
Сам этот патч, возможности JSONPath и история вопроса обсуждались в деталях в отдельной статье здесь на хабре. JSONPath — серьезное достижение Postgres Professional и одно из главных новшеств PostgreSQL 12 вообще.
В 2014 году А.Коротковым, О.Бартуновым и Ф.Сигаевым было разработано расширение jsquery, вошедшее в результате в версию Postgres Pro Standard 9.5 (и в более поздние версии Standard и Enterprise). Оно дает дополнительные, очень широкие возможности для работы с json(b).
Когда появился стандарт SQL:2016, оказалось, что его семантика не так уж сильно отличается от нашей в расширении jsquery. Не исключено, что авторы стандарта даже поглядывали на jsquery, изобретая JSONPath. Нашей команде пришлось реализовывать немного по-другому то, что у нас уже было и, конечно, много нового тоже.
Хотя специальный патч с функциями до сих пор не закоммичен, в патче JSONPath уже есть ключевые функции для работы с JSON(B), например:
Кроме того, были оптимизированы и некоторые функции, которые уже работали с JSON раньше. Этим успешно занимался Никита Глухов.
Например, оператор
1. Поддержка JSONPath
(В Release Notes это звучит как Add support for the SQL/JSON path language (Nikita Glukhov, Teodor Sigaev, Alexander Korotkov, Oleg Bartunov, Liudmila Mantrova)
Сам этот патч, возможности JSONPath и история вопроса обсуждались в деталях в отдельной статье здесь на хабре. JSONPath — серьезное достижение Postgres Professional и одно из главных новшеств PostgreSQL 12 вообще.
В 2014 году А.Коротковым, О.Бартуновым и Ф.Сигаевым было разработано расширение jsquery, вошедшее в результате в версию Postgres Pro Standard 9.5 (и в более поздние версии Standard и Enterprise). Оно дает дополнительные, очень широкие возможности для работы с json(b).
Когда появился стандарт SQL:2016, оказалось, что его семантика не так уж сильно отличается от нашей в расширении jsquery. Не исключено, что авторы стандарта даже поглядывали на jsquery, изобретая JSONPath. Нашей команде пришлось реализовывать немного по-другому то, что у нас уже было и, конечно, много нового тоже.
Хотя специальный патч с функциями до сих пор не закоммичен, в патче JSONPath уже есть ключевые функции для работы с JSON(B), например:
jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') возвращает 3, 4, 5
jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') возвращает 0 записейКроме того, были оптимизированы и некоторые функции, которые уже работали с JSON раньше. Этим успешно занимался Никита Глухов.
Например, оператор
#>>, соответствующий функциям jsonb_each_text() и jsonb_array_elements_text(), раньше достаточно быстро преобразовывал JsonbValue в text, но работал неторопливо с другими типами. Сейчас всё работает быстро.Вокруг Света за 4 Секунды на Columnstore (Часть 1)
18 min
В этой статье я собираюсь рассмотреть вопрос повышения скорости отчетов. Под отчетом я понимаю любой запрос в базу данных, который использует агрегирующие функции. Также, я собираюсь затронуть вопросы, касающиеся затрачиваемых ресурсов на производство и поддержку отчетов, как людские, так и машинные.
В примерах я буду использовать набор данных, содержащий 52 608 000 записей.
На примере не сложных аналитических запасов я продемонстрирую, что даже слабый компьютер можно превратить в неплохое средство анализа «приличного» объема данных без особых усилий.
Поставив не сложные эксперименты, мы увидим, что обычная таблица не является подходящим источником для аналитических запросов.
Если читатель без труда может расшифровать аббревиатуры OLTP и OLAP, возможно есть смысл перейти сразу к разделу Columnstore
Здесь я буду краток, т.к. информации по этой теме в интернете более, чем достаточно.
Итак, на самом верхнем уровне существует всего два подхода к работе с данными: OLTP и OLAP.
OLTP — можно перевести, как моментальная обработка транзакций. На самом деле, речь идёт об онлайн обработке коротких транзакций, работающих с небольшим объёмом данных. Например, запись, обновление или удаление заказа. В подавляющем большинстве случаев заказ — это крайне малый объём данных, при обработке которого можно не бояться длительных блокировок, накладываемых современными РСУБД.
OLAP — можно перевести как аналитическая обработка большого количества транзакций за один раз. Любой отчет использует именно этот подход, ведь в подавляющем большинстве случаев отчет выдаёт сводные, агрегированные цифры по определённым разрезам.
В примерах я буду использовать набор данных, содержащий 52 608 000 записей.
На примере не сложных аналитических запасов я продемонстрирую, что даже слабый компьютер можно превратить в неплохое средство анализа «приличного» объема данных без особых усилий.
Поставив не сложные эксперименты, мы увидим, что обычная таблица не является подходящим источником для аналитических запросов.
Если читатель без труда может расшифровать аббревиатуры OLTP и OLAP, возможно есть смысл перейти сразу к разделу Columnstore
Два подхода к работе с данными
Здесь я буду краток, т.к. информации по этой теме в интернете более, чем достаточно.
Итак, на самом верхнем уровне существует всего два подхода к работе с данными: OLTP и OLAP.
OLTP — можно перевести, как моментальная обработка транзакций. На самом деле, речь идёт об онлайн обработке коротких транзакций, работающих с небольшим объёмом данных. Например, запись, обновление или удаление заказа. В подавляющем большинстве случаев заказ — это крайне малый объём данных, при обработке которого можно не бояться длительных блокировок, накладываемых современными РСУБД.
OLAP — можно перевести как аналитическая обработка большого количества транзакций за один раз. Любой отчет использует именно этот подход, ведь в подавляющем большинстве случаев отчет выдаёт сводные, агрегированные цифры по определённым разрезам.
Анатомия KD-Деревьев
14 min

Эта статья полностью посвящена KD-Деревьям: я описываю тонкости построения KD-Деревьев, тонкости реализации функций поиска 'ближнего' в KD-Дереве, а также возможные 'подводные камни', которые возникают в процессе решения тех или иных подзадач алгоритма. Дабы не запутывать читателя терминологией(плоскость, гипер-плоскость и т.п), да и вообще для удобства, полагается что основное действо разворачивается в трехмерном пространстве. Однако же, где нужно я отмечаю, что мы работаем в пространстве другой размерности. По моему мнению статья будет полезна как программистам, так и всем тем, кто заинтересован в изучении алгоритмов: кто-то найдет для себя что-то новое, а кто-то просто повторит материал и возможно, в комментариях дополнит статью. В любом случае, прошу всех под кат.
Inside The JeMalloc. Базовые Структуры Данных: Pairing Heap & Bitmap Tree
7 min

Тема Аллокаторов частенько всплывает на просторах интернета: действительно, аллокатор — эдакий краеугольный камень, сердце любого приложения. В этой серии постов я хочу в подробностях рассказать о одном весьма занимательном и именитом аллокаторе — JeMalloc, поддерживаемый и развиваемый Facebook и используемый, например, в bionic[Android] lib C.
В сети мне не удалось найти каких-либо подробностей, полностью раскрывающих душу данного аллокатора, что по итогу сказалось на невозможности сделать какие-либо выводы о применимости JeMalloc при решении той или иной задачи. Материала вышло очень много и, дабы читать его было не утомительно, начать предлагаю с основ: Базовых Структур Данных используемых в JeMalloc.
Под катом рассказываю о Pairing Heap и Bitmap Tree, формирующих фундамент JeMalloc. На данном этапе я не затрагиваю тему многопоточности и Fine Grained Locking, однако, продолжая серию постов, обязательно расскажу про эти вещи, ради которых, собственно, и создается разного рода Экзотика, в частности и та, что описывается ниже.
Руководство по ассемблеру Go
12 min
Translation

Прежде чем заняться реализацией runtime и изучением стандартной библиотеки, необходимо освоить абстрактный ассемблер Go. Надеюсь, это руководство поможет вам быстро овладеть нужными знаниями.
RE: Боль и слёзы в Svelte 3
9 min
Вместо предисловия
Данный пост является ответом на вчерашнюю статью «Боль и слёзы в Svelte 3» и появился как следствие сильно «располневшего» комментария к оригинальной статье, который я решил оформить в виде поста. Ниже я буду использовать слово автор для отсылки к автору оригинальной статьи и позволю себе сделать некоторые уточнения по всем пунктам. Поехали!

Как не ошибиться с конкурентностью в Go
12 min
Почему мы вообще хотим писать конкурентный код? Потому что процессоры перестали расти по герцовке и начали расти по ядрам. С каждым годом увеличивается количество ядер процессора, и мы хотим их эффективно утилизировать. Go — тот язык, который создан для этого. В документации так и написано.
Мы берём Go, начинаем писать конкурентный код. Конечно, ожидаем, что легко сможем обуздать мощь каждого ядра нашего процессора. Так ли это?
Меня зовут Артемий. Этот пост — вольная расшифровка моего доклада с GopherCon Russia. Он появился как попытка дать толчок людям, которые хотят разобраться, как писать хороший, конкурентный код.
Видео с конференции GopherCon Russia
Разбираемся с интерфейсами в Go
10 min
Tutorial
Translation

В последние несколько месяцев я проводил исследование, в котором спрашивал людей, что им трудно понять в Go. И заметил, что в ответах регулярно упоминалась концепция интерфейсов. Go был первым языком с интерфейсами, который я использовал, и я помню, что в то время эта концепция казалась сильно запутанной. И в этом руководстве я хочу сделать вот что:
- Человеческим языком объяснить, что такое интерфейсы.
- Объяснить, чем они полезны и как вы можете использовать их в своём коде.
- Поговорить о том, что такое
interface{}(пустой интерфейс). - И пройтись по нескольким полезным типам интерфейсов, которые вы можете найти в стандартной библиотеке.
Продуктовая разработка на Go: история одного проекта
9 min

Всем привет! Меня зовут Максим Рындин, я тимлид двух команд в Gett – Billing и Infrastructure. Хочу рассказать про продуктовую веб-разработку, которую мы в Gett ведем преимущественно на языке Go. Я расскажу, как в 2015-2017 годах мы переходили на этот язык, почему вообще его выбрали, с какими проблемами столкнулись во время перехода и какие решения нашли. А о текущей ситуации расскажу уже в следующей статье.
Для тех, кто не знает: Gett — это международный сервис заказа такси, который был основан в Израиле в 2011 году. Сейчас Gett представлен в 4 странах: Израиль, Великобритания, Россия и США. Основные продукты нашей компании — это мобильные приложения для клиентов и водителей, веб-портал для корпоративных клиентов, где можно заказать машину, и еще куча внутренних админок, через которые наши сотрудники настраивают тарифные планы, подключают новых водителей, мониторят случаи мошенничества и многое другое. В конце 2016 года в Москве открылся глобальный офис R&D, который работает в интересах всей компании.
Zen2. Эволюция платформы AM4 на примере Ryzen 7 3700x
7 min
AMD продолжает развивать свою долгоиграющую платформу AM4. Недавно вышло новое поколение процессоров Ryzen на микроархитектуре Zen 2. Вообще, цикл развития архитектур AMD стал чем-то напоминать тик-так Intel, но не 1 в 1. Так, второе поколение Ryzen было скорее вариацией на тему изначальной архитектуры Zen с исправлением основных косяков и реализованное на чуть более тонком техпроцессе, что нашло отражение даже в названии архитектуры чипов 2xxx — Zen+. Сейчас же AMD выкатили чиплетную архитектуру. Получилась прямо классическая спираль развития — AMD в 2003 году первыми начали перенос компонент северного моста в ядра, начав с переноса в процессорах линейки K8 контроллера памяти в CPU и закончив тем, что Ryzen тысячной и двухтысячной серий представляли из себя полноценные SoC, так в 2019 они же снова вынесли северник в отдельный кристалл, пусть и на той же подложке, что и ядра.
Теоретических материалов, обзоров и тестов хватает и на русском (например Разгон Matisse или в поисках предела. Обзор архитектуры Zen 2), и на английском языках, мне же захотелось лично сравнить свежий AMD Ryzen 7 3700x с 2700x на моих тестах, аналогичным использованных в прошлых постах (пост 1, пост 2).
Пример создания Makefile для Go-приложений
7 min
Tutorial
Translation
В этом руководстве мы рассмотрим, как разработчик Go может использовать Makefile при разработке собственных приложений.
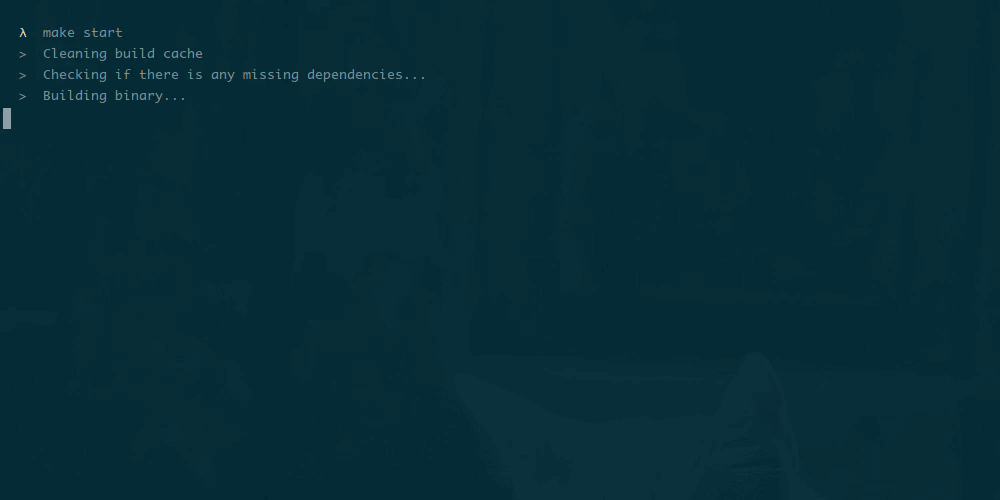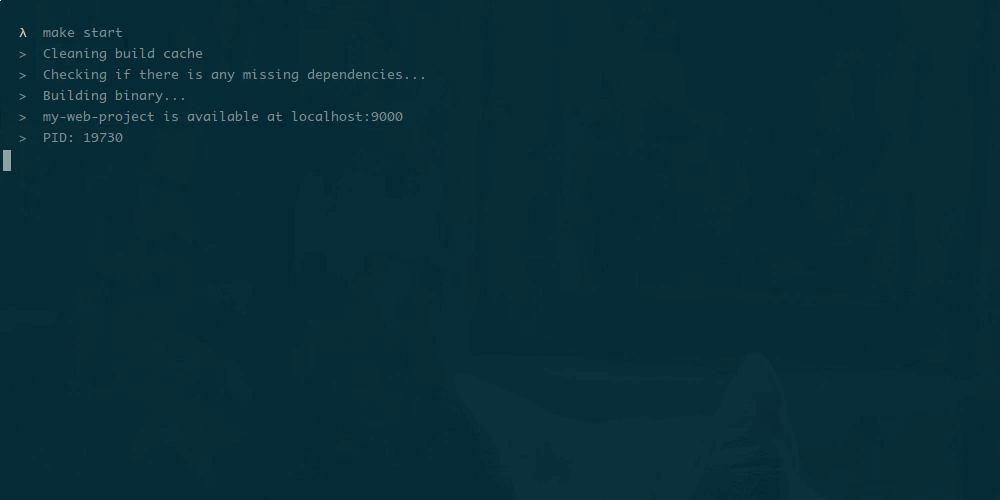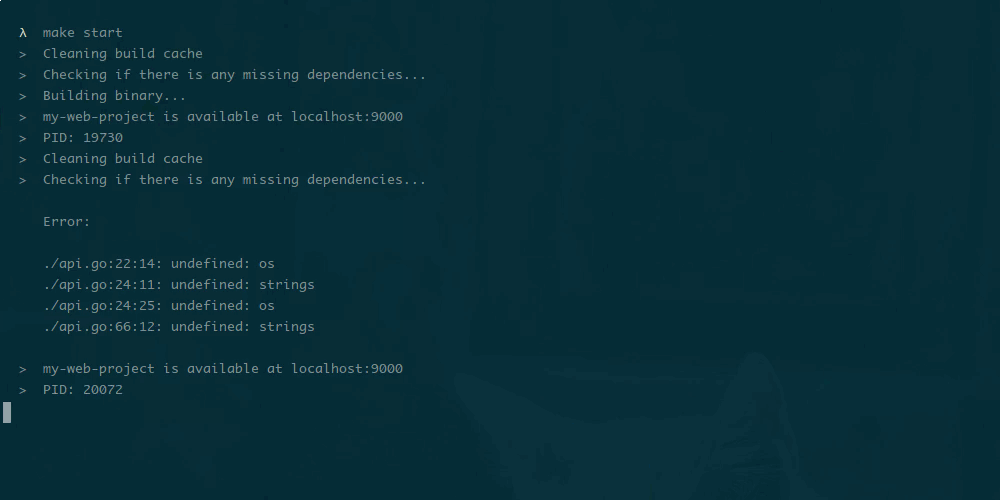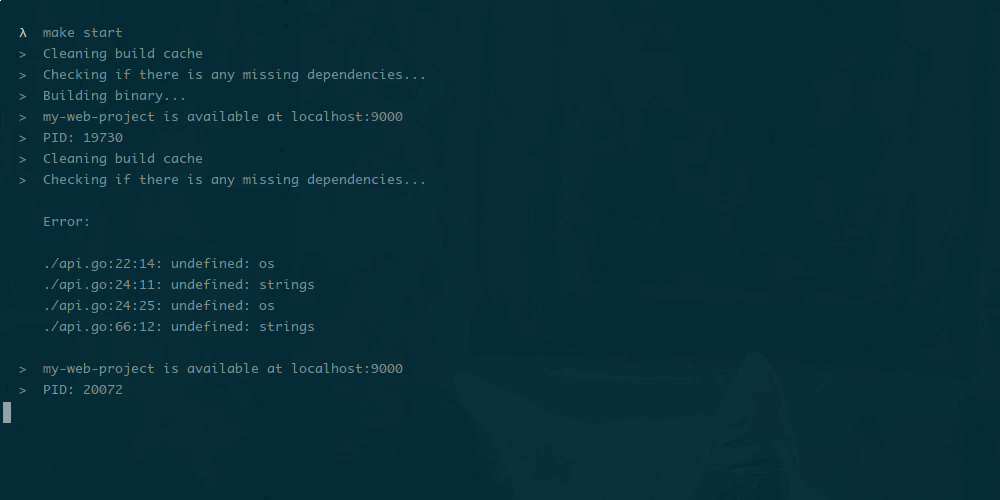
Makefile — невероятно полезный инструмент автоматизации, который можно использовать для запуска и сборки приложений не только на Go, но и на большинстве других языков программирования.
Его часто можно увидеть в корневом каталоге множества Go приложений на Github и Gitlab. Он широко используются в качестве инструмента для автоматизации задач, которые часто сопровождают разработчиков.
Если вы используете Go для создания веб-сервисов, то Makefile поможет решить следующие задачи:
Что такое Makefile-ы?
Makefile — невероятно полезный инструмент автоматизации, который можно использовать для запуска и сборки приложений не только на Go, но и на большинстве других языков программирования.
Его часто можно увидеть в корневом каталоге множества Go приложений на Github и Gitlab. Он широко используются в качестве инструмента для автоматизации задач, которые часто сопровождают разработчиков.
Если вы используете Go для создания веб-сервисов, то Makefile поможет решить следующие задачи:
- Автоматизация вызова простых команд, таких как: compile, start, stop, watch и т. д.
- Управление специфичными для проекта переменными окружения. Он должен подключать файл .env.
- Режим разработки, который автоматически компилируется при изменении.
- Режим разработки, который показывает ошибки компиляции.
- Определение GOPATH для конкретного проекта, чтобы мы могли хранить зависимости в папке vendor.
- Упрощенный мониторинг файлов, например, make watch run = «go test. / ...»
Простые методы оптимизации программ Go
11 min
Translation
Я всегда забочусь о производительности. Точно не знаю, почему. Но меня просто бесят медленные сервисы и программы. Похоже, я не одинок.
По опыту, низкая производительность проявляется одним из двух способов:
В тестах A/B мы попытались замедлять выдачу страниц с шагом 100 миллисекунд и обнаружили, что даже очень небольшие задержки приводят к существенному падению доходов. — Грег Линден, Amazon.com
По опыту, низкая производительность проявляется одним из двух способов:
- Операции, которые хорошо выполняются в небольших масштабах, становятся нежизнеспособными с ростом числа пользователей. Обычно это операции O(N) или O(N²). Когда база пользователей мала, всё работает отлично. Продукт спешат вывести на рынок. По мере роста базы возникает всё больше неожиданных патологических ситуаций — и сервис останавливается.
- Много отдельных источников неоптимальной работы, «смерть от тысячи порезов».